A few months ago, I wrote a post on the DuckDB blog where I explained how DuckDB’s SQL can express operations that developers typically implement with UNIX commands. Then earlier this week, I published a light-hearted social media post about DuckDB beating the UNIX wc -l command for counting the lines in a CSV file by a significant margin (1.2 vs. 2.9 seconds).
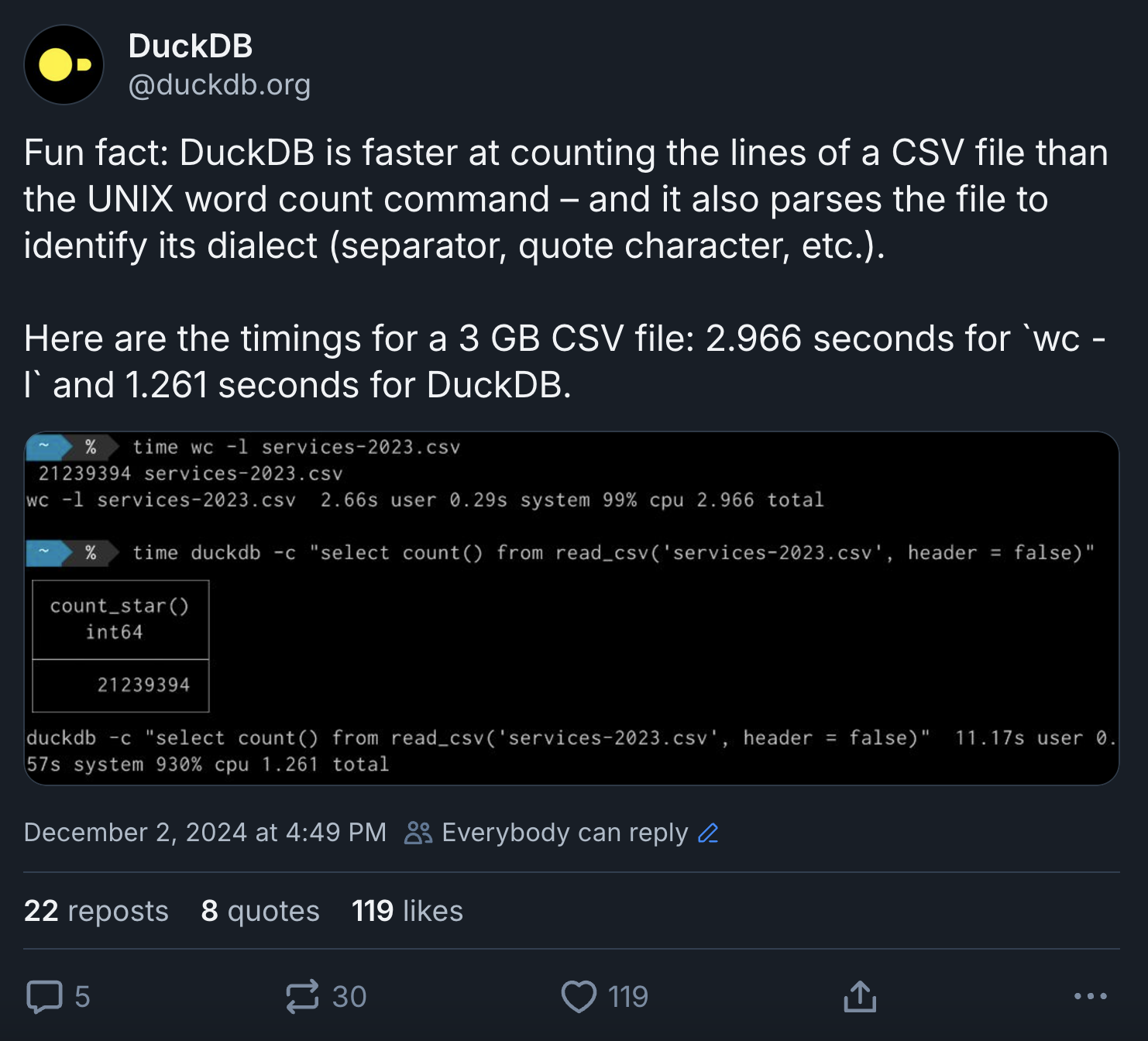
This post received a lot of feedback with the criticisms centered around two points:
- DuckDB uses a lot of CPU time and only wins thanks to multi-threading.
- The
wccommand on macOS is quite inefficient and it’s much faster in Linux distributions.
These are valid points and I was keen to learn more about how DuckDB stacks up against UNIX tools at their best, so today I conducted a few new experiments on Ubuntu 24.04 running on a c7gd.16xlarge instance, which has 64 AWS Graviton 3 vCPU cores (using the ARM64/AArch64 architecture), two NVMe SSDs, and loads of memory. The built-in coreutils packages include wc version 9.4 and grep version 3.11.
To set up the experiments, I updated the existing system packages and installed the following packages:
sudo apt update && sudo apt upgrade && sudo apt install -y hyperfine parallel
I created a RAID-0 array from the SSDs to eliminate disk access as a potential performance bottleneck.
Counting One Year of Railway Services
I first reproduced the experiments in the original social media post on the server. This used one year’s worth of railway data (mirror: services-2023.csv.zst, ~300 MB).
On the beefy Linux machine, wc -l services-2023.csv completes in 0.6 seconds, while DuckDB takes 0.9 seconds – this is a clear win for wc.
Here are the detailed results with 10 runs performed by hyperfine:
$ hyperfine "wc -l services-2023.csv"
Benchmark 1: wc -l services-2023.csv
Time (mean ± σ): 639.2 ms ± 6.4 ms [User: 348.4 ms, System: 291.2 ms]
Range (min … max): 632.2 ms … 651.2 ms 10 runs
$ hyperfine "duckdb -c \"SELECT count() FROM read_csv('services-2023.csv', header = false)\""
Benchmark 1: duckdb -c "SELECT count() FROM read_csv('services-2023.csv', header = false)"
Time (mean ± σ): 939.5 ms ± 18.1 ms [User: 15788.8 ms, System: 889.1 ms]
Range (min … max): 906.7 ms … 962.7 ms 10 runs
Counting 5 Years of Railway Services
Let’s extend the dataset to include 5 years of railway services, amounting to ~15 GB in CSV files with 108 million lines in total. With this large dataset DuckDB can make use of all cores and can beat single-threaded wc even on Linux: looking at the wall clock times, wc takes 3.2 seconds, while DuckDB only takes 2.2 seconds (and a lot of CPU time).
$ hyperfine "wc -l services-*.csv"
Benchmark 1: wc -l services-*.csv
Time (mean ± σ): 3.228 s ± 0.011 s [User: 1.764 s, System: 1.464 s]
Range (min … max): 3.213 s … 3.245 s 10 runs
$ hyperfine "duckdb -c \"SELECT count() FROM read_csv('services-*.csv', header = false)\""
Benchmark 1: duckdb -c "SELECT count() FROM read_csv('services-*.csv', header = false)"
Time (mean ± σ): 2.167 s ± 0.025 s [User: 79.925 s, System: 1.989 s]
Range (min … max): 2.132 s … 2.217 s 10 runs
One approach to making wc faster is using uutils coreutils, a Rust rewrite of GNU coreutils. The uutils wc implementation is still single-threaded but it’s faster than its GNU counterpart and also faster than DuckDB, finishing in 1.8 seconds.
$ hyperfine "~/.cargo/bin/coreutils wc -l services-*.csv"
Benchmark 1: ~/.cargo/bin/coreutils wc -l services-*.csv
Time (mean ± σ): 1.839 s ± 0.022 s [User: 0.364 s, System: 1.475 s]
Range (min … max): 1.802 s … 1.880 s 10 runs
Another approach we can take is to unlock multi-threaded processing for wc.
To achieve this, we can use the GNU Parallel command.
For simplicity’s sake, we’ll first paste the files together with cat outside of the measured experiment time:
$ cat services-*.csv > services.csv
We can then take this file and chunk it into blocks of approximately 500 MB, run wc -l and summarize the partial counts with awk:
$ hyperfine "parallel --block 500M --pipepart -a services.csv wc -l | awk '{s+=\$1} END {print s}'"
Benchmark 1: parallel --block 500M --pipepart -a services.csv wc -l | awk '{s+=$1} END {print s}'
Time (mean ± σ): 464.0 ms ± 6.8 ms [User: 2132.6 ms, System: 10797.8 ms]
Range (min … max): 453.8 ms … 473.7 ms 10 runs
Parallel execution allows the GNU wc to finish in 0.5 seconds and take the lead.
To sum up the results so far, the runtimes for counting ~100M lines are as follows:
| Toolchain | Runtime |
|---|---|
wc from GNU coreutils |
3.2 s |
| DuckDB v1.1.3 | 2.2 s |
wc from uutils coreutils |
1.8 s |
wc from GNU coreutils with parallel |
0.5 s |
Counting the Intercity Services
Let’s take a slightly more complex problem: counting the number of Intercity services. There are 23.9 million Intercity services out of 108 million records, so we filter to 1/4 of the lines, then count them.
With UNIX tools, this problem can be solved by using grep. If we assume that the CSV file doesn’t have commas in its fields (which is safe to assume for these CSVs), we can simply run:
$ grep ',Intercity,' services-*.csv | wc -l
Let’s see the results for the classic tools (grep with GNU wc), the Rust tools (ripgrep with uutils wc), and DuckDB.
$ hyperfine "grep ',Intercity,' services-*.csv | wc -l"
Benchmark 1: grep ',Intercity,' services-*.csv | wc -l
Time (mean ± σ): 12.309 s ± 0.131 s [User: 9.525 s, System: 5.536 s]
Range (min … max): 12.154 s … 12.551 s 10 runs
$ hyperfine "rg ',Intercity,' services-*.csv | ~/.cargo/bin/coreutils wc -l"
Benchmark 1: rg ',Intercity,' services-*.csv | ~/.cargo/bin/coreutils wc -l
Time (mean ± σ): 2.990 s ± 0.045 s [User: 4.034 s, System: 4.880 s]
Range (min … max): 2.896 s … 3.064 s 10 runs
$ hyperfine "duckdb -c \"SELECT count(*) FROM 'services-*.csv' WHERE #3='Intercity'\""
Benchmark 1: duckdb -c "SELECT count(*) FROM 'services-*.csv' WHERE #3='Intercity'"
Time (mean ± σ): 2.791 s ± 0.023 s [User: 81.529 s, System: 1.999 s]
Range (min … max): 2.762 s … 2.832 s 10 runs
I also tried more complex approaches with
cut -d ',' -f 3to first project the service type field but found that it made the execution slower.
So far, DuckDB is ahead. What happens if we bring parallelism back into the mix?
$ hyperfine "parallel --block 500M --pipepart -a services.csv grep ',Intercity,' | wc -l | awk '{s+=\$1} END {print s}'"
Benchmark 1: parallel --block 500M --pipepart -a services.csv grep ',Intercity,' | wc -l | awk '{s+=$1} END {print s}'
Time (mean ± σ): 2.691 s ± 0.049 s [User: 9.440 s, System: 15.954 s]
Range (min … max): 2.625 s … 2.760 s 10 runs
With this, the results look like this:
| Toolchain | Runtime |
|---|---|
grep and wc from GNU coreutils |
12.5 s |
ripgrep with wc from uutils coreutils |
3.0 s |
| DuckDB v1.1.3 | 2.8 s |
grep and wc from GNU coreutils with grep |
2.7 s |
It beat DuckDB – just! So, yes, you can make wc run really fast for line counting but it takes some work and it can be very error-prone for more complex computations.
I also tried parallel with
ripgrepand uutilswcbut using them didn’t make much difference – they produced the result in ~2.9 seconds.
Summary
In this post I showed how different wc variants (GNU, uutils, parallelized) stack up against DuckDB.
Based on these results and the results of the previous experiments, I would say: it depends!
- On an out-of-the-box MacBook, DuckDB is the likely winner.
- On a small Linux server,
wcwill win most of the time. - On a large Linux server, it can go both ways depending on the dataset size, the
wcimplementation used (GNU vs. uutils), whether hand-rolled parallelism is applied, etc.
I definitely wouldn’t recommend anyone to ditch wc -l for counting lines in favor of DuckDB. It has a concise syntax, it is resource-efficient and is plenty fast for most cases.
However, it’s surprising that DuckDB is not only close to wc but is often faster thanks to its highly efficient parallel CSV reader.
PS
While I try to make sure that these benchmarks are executed correctly, please don’t take them too seriously. Benchmarking involves a lot of nuances – I have co-authored and maintain a large TPC-style benchmark suite and I’m well aware that measuring DuckDB vs. coreutils is just a fun microbenchmark. It offers some insight into system performance but it isn’t intended as a comprehensive evaluation of these tools.
Update (2024-12-05)
Bernhard Kauer pointed out an issue with the use of awk in my script. I re-ran the experiments and updated the text accordingly.
Update (2025-01-12)
Pádraig Brady pointed out that I did not report the tools’ versions in the post, so I added these. He also referred me to his UNIX parallel tools benchmarks.